04. 데이터 파이프라인
데이터 파이프라인이란 데이터를 한 장소에서 다른 장소로 옮기는 것을 의미
API → Database
Database → Database
Database → BI Tool
데이터 파이프라인이 필요한 경우
- 다양한 데이터 소스들로부터 많은 데이터를 생성하고 저장하는 서비스
- 데이터 사일로: 마케팅, 브랜딩, 어카운팅, 세일즈, 오퍼레이션 등 각 영역의 데이터가 서로 고립되어 있는 경우 (통합 필요)
- 실시간 혹은 높은 수준의 데이터 분석이 필요한 비지니스 모델클라우드 환경으로 데이터 저장
데이터 아키텍쳐시 고려사항
API (데이터 추출) → AWS Lamda (DATA Processing) → Amazon S3(저장소) → 분석 → BI (Visualization)
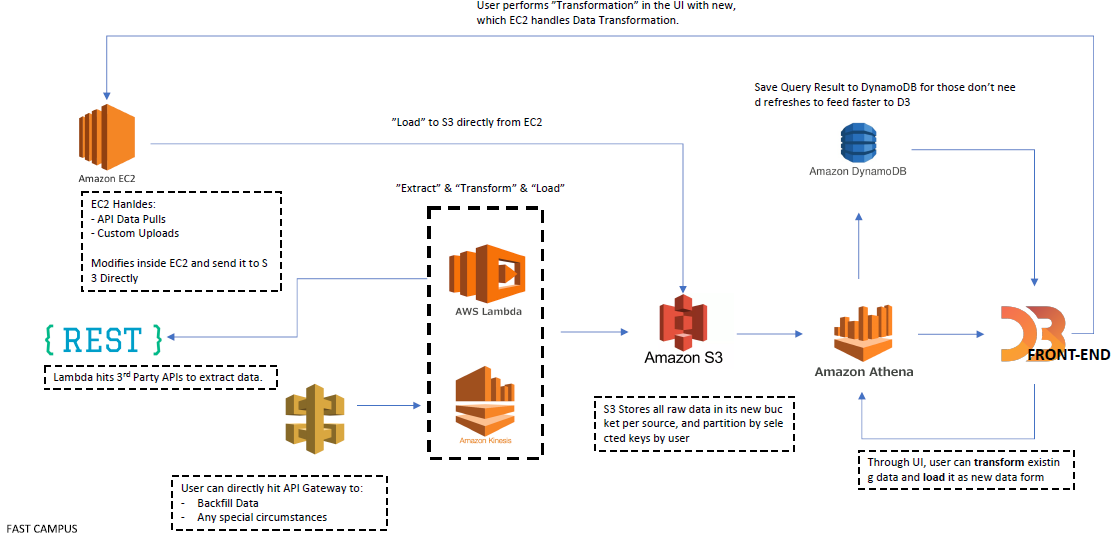
데이터 파이프라인 구축 시 고려 사항
- Scalability: 데이터가 기하급수적으로 늘어났을때도 작동하는가?
- Stability: 에러, 데이터 플로우 등 다양한 모니터링 관리
- Security: 데이터 이동간 보안에 대한 리스크는 무엇인가?
05. 자동화의 이해
데이터 프로세싱 자동화란
데이터 프로세싱 자동화란 필요한 데이터를 추출, 수집, 정제하는 프로세싱을 최소한의 사람 input으로 머신이 운영하는 것을 의미
예) Spotify 데이터를 하루에 한번 API를 통해서 클라우드 데이터베이스로 가져온다고 했을 때 매번 사람이 데이터 파이프라인을 작동하는 것이 아니라 크론탭 등 머신 스케쥴링을 통해 자동화
자동화를 위해 고려할 사항
- 데이터 프로세싱 스텝들
- 에러 핸들링 및 모니터링
- 트리거 / 스케쥴링
데이터 프로세싱 스텝

에러 핸들링 및 모니터링
Python Logging Package

Cloud Logging Systems
• AWS Cloudwatch
• AWS Data Pipeline Errors
Trigger & Scheduling

06. 엔드 투 엔드 아키텍쳐
빅데이터 처리를 위한 데이터 레이크
Data Source → Amazon S3 (빅데이터 저장소) → Spark (Amazon EMR) → Amazon Redshift → Amazon Athena / Amazon RDS

넷플릭스 데이터 시스템 예시

우버 데이터 아키텍쳐

07. Spotify 프로젝트 데이터 아키텍쳐
Ad hoc VS Automated
- Ad hoc
비정기적 분석
분석 환경 구축은 서비스를 지속적으로 빠르게 변화시키기 위해 필수적인 요소
이니셜 데이터 삽입 (최초 데이터 삽입 작업), 데이터 Backfill 등을 위해 Ad hoc 데이터 프로세싱 시스템 구축 필요
- Automated
결국 구축해야 하는 자동화 - 이벤트, 스케쥴 등 트리거를 통해 자동화 시스템 구축
아티스트 관련 데이터 수집 프로세스
*Ad Hoc Data Job: 최초 이니셜 데이터 삽입 작업 (ex. 몇 천명의 아티스트 데이터를 최초로 불러오는 작업)

데이터 분석 환경 구축
S3(Storage Layer) 에 저장된 데이터 기반으로 →
Amazon Athena(Query Layer - SQL 기반) 통해 Ad hoc 분석 →
Spark(Compute Layer) 통해 Computing →
redash / Aache Zeppelin 통해 Analysis / Visualizaion

서비스 관련 데이터 프로세스
Computing 통해 유사도 계산 → 다이나모 DB → Chatbot에서 다이나모 DB에게 바로 필요한 데이터 주는 환경 구축

큰 틀에서 어떤 식으로 데이터를 수집하고 이게 Chatbot을 통해 어떤 식으로 구현되는지까지,
그리고 그 안에서 여러가지 경우의 수를 고려하여 필요한 데이터를 자동화는 부분까지 알아봤다.
다음 포스팅에서는 데이터 엔지니어 기초에 대해 이어서 학습해보자.
※ 위 글은 FastCampus 강의를 바탕으로 정리한 포스팅입니다.
'AI & Tech > DATA Engineering' 카테고리의 다른 글
| [데이터 엔지니어링] 01-1. 데이터 엔지니어링 개요 (0) | 2022.10.19 |
|---|

댓글